Introduction to AWQ Algorithm#
1. AWQ Overview#
AWQ (Activation-aware Weight Quantization) is a weight quantization method designed for large language models (LLMs). The core idea is that not all weights in a model contribute equally to its performance. AWQ focuses on identifying and better preserving the weights that are most critical — specifically, those connected to high-activation features.
Instead of treating all weights uniformly during quantization, AWQ scales important weights to make them more distinguishable in low-bit formats, reducing quantization error without sacrificing model accuracy. This scaling is compensated during inference to maintain the correctness of the final output.
The scaling factors are derived from the average magnitude of input activations on a per-channel basis and are further modulated by a tunable hyperparameter. Increasing this scaling factor preserves more fine-grained information in salient channels, thereby enhancing fidelity and improving accuracy. Conversely, reducing the scaling factor enables more aggressive quantization, lowering memory footprint and computational overhead, and thus improving compression efficiency. Through this mechanism, AWQ achieves a practical trade-off, delivering significant efficiency gains without incurring unacceptable accuracy degradation in LLM applications.
For technical details, please refer to the original paper: Activation-aware Weight Quantization for LLM Compression
2. Quark AWQ Workflow#
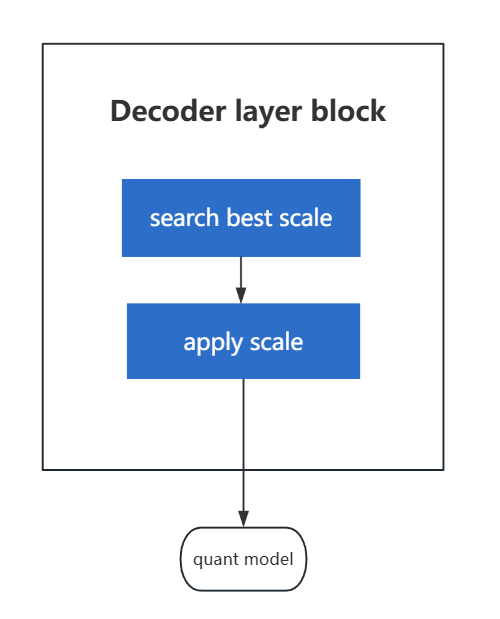
As illustrated in the figure, the AWQ algorithm first identifies the decoder layers from the model structure. It then processes each block individually: for every block, the algorithm is divided into two phases — the search-best-scale phase and the apply-scale phase:
search-best-scale
In the search-best-scale phase, a grid search is performed to compare the loss with the non-quantized version, and the scale that minimizes the loss is selected as the best scale.
apply-scale
In the apply-scale phase, the scale is fused into the weight parameters of both
prev_opandlayers.
3. Quark AWQ Config#
For example (AWQ config for Llama3)#
{
"name": "awq",
"scaling_layers": [
{
"prev_op": "input_layernorm",
"layers": ["self_attn.q_proj", "self_attn.k_proj", "self_attn.v_proj"],
"inp": "self_attn.q_proj",
"module2inspect": "self_attn"
},
{
"prev_op": "self_attn.v_proj",
"layers": ["self_attn.o_proj"],
"inp": "self_attn.o_proj"
},
{
"prev_op": "post_attention_layernorm",
"layers": ["mlp.gate_proj", "mlp.up_proj"],
"inp": "mlp.gate_proj",
"module2inspect": "mlp"
},
{
"prev_op": "mlp.up_proj",
"layers": ["mlp.down_proj"],
"inp": "mlp.down_proj"
}
],
"model_decoder_layers": "model.layers"
}
Field Descriptions#
model_decoder_layers#
Type:
stringDescription: Path to decoder blocks (e.g.,
"model.layers")
scaling_layers#
Type:
list of dictsDescription: Defines how to scale layers in each decoder block.
module2inspect#
Type:
stringDescription:
module2inspectis the minimal module for adjustment in the AWQ algorithm. We perform a grid search to compare the MSE loss between the quantized output and the float output, identify the scale that minimizes the loss as the optimal scale, and then, during the apply-scale phase, integrate this scale into the weights of the preceding operation and the layers.
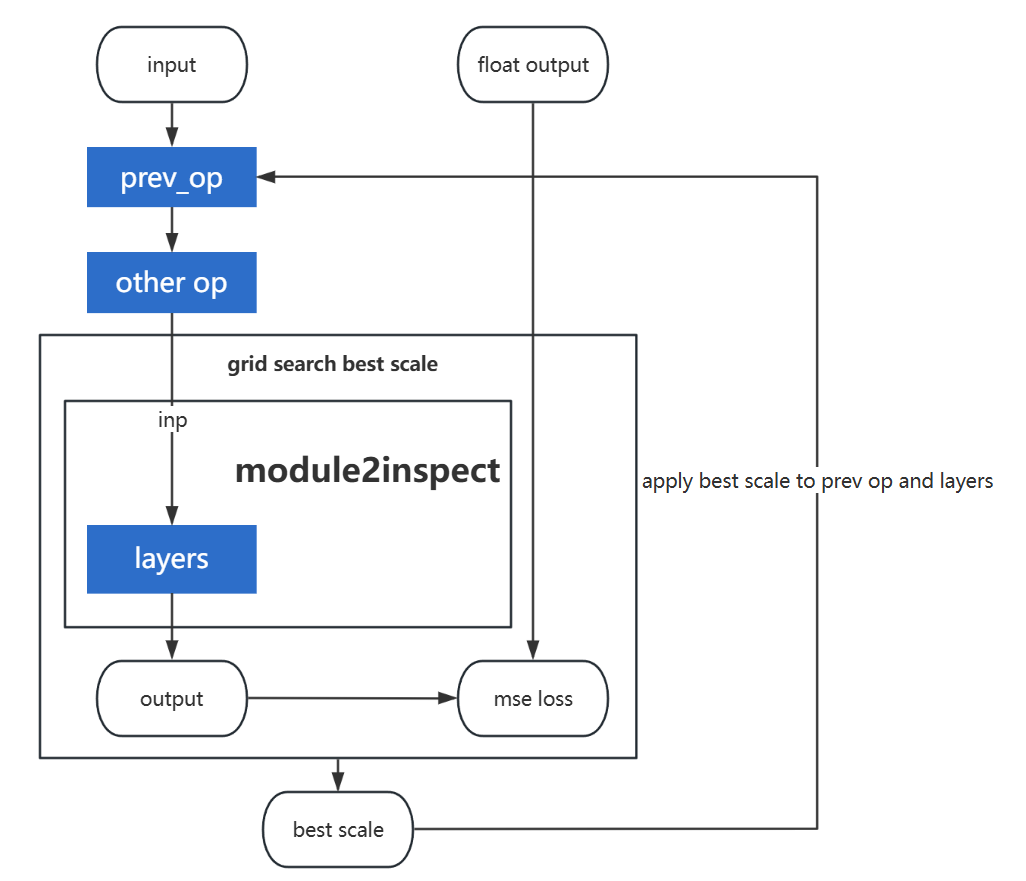
prev_op#
Type:
stringDescription: The module preceding the
layers, which can be either a linear layer or a layer normalization. During the apply-scale phase, the scale is fused into prev_op.
layers#
Type:
list of stringDescription: The
layerstypically consist of one or more linear modules. By shifting the quantization burden from the input oflayersto their weights, we effectively reduce the quantization error withinlayers.
inp#
Type:
stringDescription: The layer whose input is used for scaling. Typically, inp corresponds to one of the modules within
layers.
How to Write Your Own AWQ Config#
Find decoder layer path Use
print(model)to locate the decoder blocks. The decoder is typically defined as annn.Sequential. Specify the decoder-layer module name as the value ofmodel_decoder_layers.Identify quantized layers Locate the linear layers within the attention and MLP components of each decoder block, and record each linear layer’s module name as the value of
layers.Note
The module name should be written relative to the current decoder block. For example, instead of
model.layers[5].self_attn.q_proj, it should be written asself_attn.q_proj.Define ``prev_op`` - ``layers`` pair From the
layersidentified in Step 2, trace upward along the computation path to find a linear layer or a layer normalization as theprev_op, with the requirement that no non-linear layer exists betweenprev_opandlayers.If multiple
layersshare the sameprev_op, merge them.Example:
{ "prev_op": "input_layernorm", "layers": ["self_attn.q_proj", "self_attn.k_proj", "self_attn.v_proj"] }Define ``model2inspect`` and ``inp``
model2inspectis annn.Module, which serves as the minimal unit used to search for the optimal scale of aprev_op–layerspair.In the AWQ config, you should specify the module name of this
nn.Module.It must at least include the target layers.
Advanced users may expand the scope of
model2inspectto potentially achieve higher accuracy.If this value is left empty,
model2inspectdefaults to the target layers itself.If
layersis an array, you must explicitly specifymodel2inspect.
inpdenotes the first operator (module) insidemodel2inspect.In the AWQ config, the user should specify the module name of this operator.
A PyTorch forward hook is attached to this operator to capture its input tensor, which will then be used as the calibration input for
model2inspect.
4. AWQ Code Call Example#
This is a code snippet demonstrating AWQ quantization. We also provide a complete end-to-end demo: AWQ Demo
def quantize_model_pipeline(
model: PreTrainedModel,
calib_dataloader: DataLoader,
) -> PreTrainedModel:
template = LLMTemplate.get(
model_type=model.config.model_type
)
quant_config = template.get_config(scheme="uint4_wo_128", algorithm=["awq"])
quantizer = ModelQuantizer(quant_config, multi_device=True)
quantized_model: PreTrainedModel = quantizer.quantize_model(model, calib_dataloader)
return quantized_model
5. Next Steps#
You can still learn more about AWQ from the following resources: