Rotation-based quantization with QuaRot#
QuaRot is a rotation-based quantization method that inserts rotation matrices into a model to reduce outliers. Reducing outliers significantly improves quantization accuracy. To illustrate the idea, consider the vector \((1, 10) \in \mathbb{R}^2\), which has an outlier value of \(10\). If you rotate it by 45 degrees clockwise, you obtain \((7.7782, 6.3640)\); the values are closer together, effectively removing the outlier. In rotation-based quantization, this idea is applied to tensors that are much larger than \(\mathbb{R}^2\) vectors.
Specifically, a rotation matrix is inserted before quantization, and its inverse is applied after quantization. Thus, at a floating-point level, the network remains unchanged, but the quantized network achieves much better accuracy.
The QuaRot method uses Hadamard matrices for rotations. An \(n \times n\) Hadamard matrix is an orthogonal matrix of the form \(\frac{1}{\sqrt{n}}A\), where the entries of \(A\) are all \(1\) and \(-1\) (see QuaRot: Outlier-Free 4-Bit Inference in Rotated LLMs). Hadamard rotations are a standard choice for rotation matrices, and Hadamard transforms can often be accelerated using hardware-optimized kernels. In 2D, there are four Hadamard rotations: 45 degrees and 135 degrees clockwise, and 45 degrees and 135 degrees counterclockwise.
QuaRot inserts four fundamental rotations into the model, called R1, R2, R3, and R4 (see SpinQuant: LLM Quantization with Learned Rotations). R1 and R2 are offline rotations incorporated directly into the model’s weights. R3 and R4 are online operations. They incur a small performance overhead since new operations are added into the model’s computation graph. However, using kernels for fast Hadamard transforms, these operations can be accelerated if necessary.
R3 and R4 are online operations. R3 is only needed when performing KV cache quantization, and R4 is only needed when performing activation quantization.
AMD Quark supports the QuaRot method for Llama models by default and can be run in one line with the quantize_quark.py script. For example, to quantize Llama 3-8B, both weights and activations, to int8 per tensor while applying the QuaRot method to perform rotations before quantization, navigate to the examples/torch/language_modeling/llm_ptq folder and run:
python quantize_quark.py --model_dir meta-llama/Meta-Llama-3-8B --quant_scheme w_int8_a_int8_per_tensor_sym --quant_algo quarot
Here are the results for the perplexity of the quantized model Llama-3-8B, with and without Quarot:
Quantization Strategy |
Algorithm |
Perplexity (Wikitext-2) |
|---|---|---|
no quantization |
6.13908052444458 |
|
w_int8_per_tensor static quantization |
N/A |
6.622321128845215 |
w_int8_per_tensor static quantization |
QuaRot (R1+R2 only) |
6.181324005126953 |
w_int8_a_int8_per_tensor static quantization |
N/A |
253.269912719726 |
w_int8_a_int8_per_tensor static quantization |
QuaRot |
6.6984167098999 |
Here is an example of creating a QuaRot configuration file for an LLM such as Qwen, which has a standard decoder-only transformer architecture:
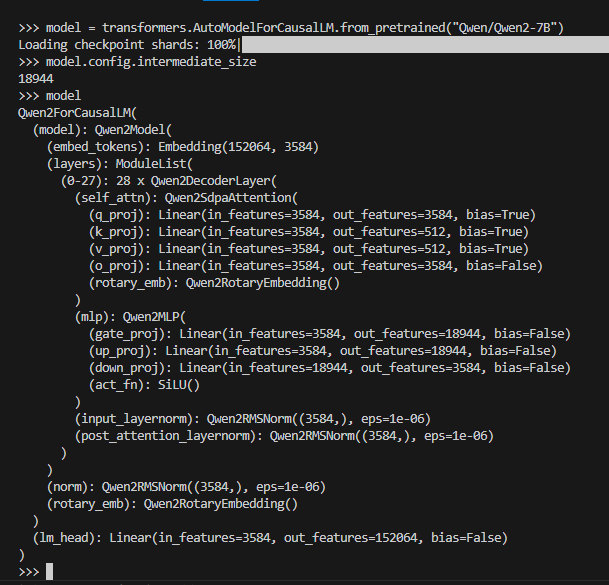
The V and O projections in the attention block can be accessed as layer.self_attn.v_proj and layer.self_attn.o_proj, respectively, for every layer in the list model.layers.
However, notice that the number of input features to the down-projection (intermediate-size) is \(18944 = 148*2^7\). AMD Quark currently only supports \(n \times n\) Hadamard matrices when \(n = m \times 2^k\), where \(m\) is in \({4, 12, 20, 40, 36, 52, 60, 108, 140, 156, 172}\) and \(k >= 0\). Therefore, the online R4 rotation cannot be performed in this case. Instead, perform only the offline operations of R1 and R2 by setting the online-had flag to False. Use the following configuration:
{
"name": "quarot",
"online-had": false,
"backbone": "model",
"model_decoder_layers": "model.layers",
"v_proj": "self_attn.v_proj",
"o_proj":"self_attn.o_proj",
"self_attn": "self_attn"
}
Here are the results for the perplexity of the quantized model Qwen2-7B, with and without quarot:
Quantization Strategy |
Algorithm |
Perplexity (Wikitext-2) |
|---|---|---|
no quantization |
7.891325950622559 |
|
w_int8_per_tensor static quantization |
N/A |
8.883856773376465 |
w_int8_per_tensor static quantization |
QuaRot (R1+R2 only) |
7.948962688446045 |
w_int8_a_int8_per_tensor static quantization |
N/A |
172.43882751464844 |
w_int8_a_int8_per_tensor static quantization |
QuaRot (R1+R2 only) |
123.24969482421875 |
To further improve W8A8 quantization, we might combine QuaRot with SmoothQuant.