Automatic Search for Model Quantization#
Overview#
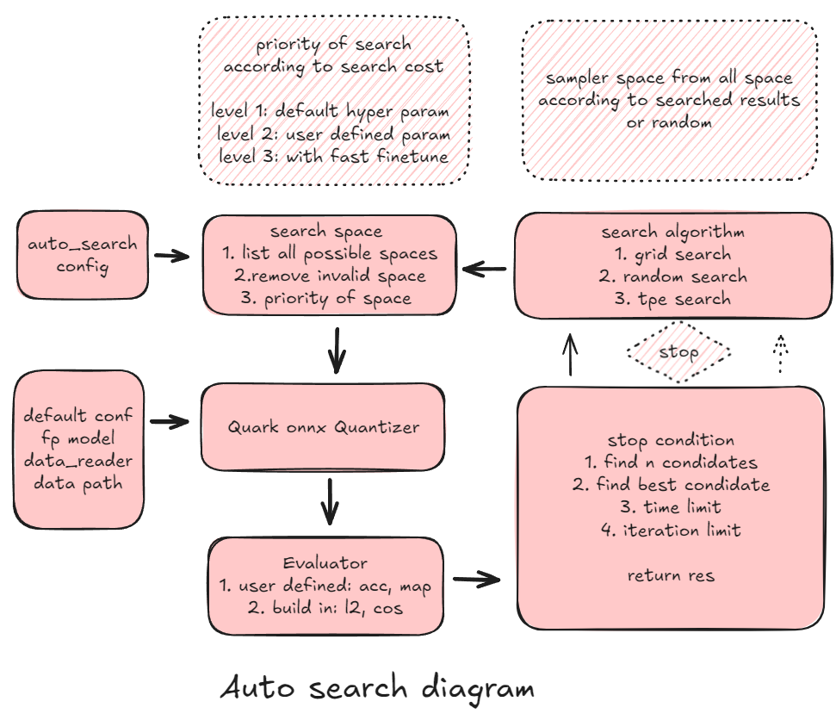
The purpose of the Automatic Search design is to find better configurations for model quantization, aiming to achieve better accuracy while reducing the resource usage of the quantized model. The design is centered around an iterative loop that continuously refines the configuration by evaluating and adjusting various quantization parameters. This loop includes several key components:
Auto Search Config: Defines the parameters for the search process.
Quantization Config: Specifies the quantization settings.
Search Space: Represents all possible configurations that can be explored.
Search Algorithm: Determines how to sample configurations from the search space.
Model Quantizer: Applies the sampled configuration to quantize the model.
Evaluator: Assesses the performance of the quantized model.
Stop Condition: Decides when to stop the search process based on the evaluation results.
The core idea is to explore different configurations to find the optimal settings for the quantized model, improving its accuracy while ensuring it meets specified performance constraints.
Components#
Search Space
The search space defines the possible configurations available for model quantization, based on the parameters set in the auto search config. Initially, all potential configurations are listed. These configurations are then filtered to remove invalid or repeated ones. Each configuration is assigned a priority that dictates the likelihood of it being sampled during the search process. The priority is determined based on factors such as the expected quantization time and resource consumption.
Search Algorithm
The search algorithm samples configurations from the search space based on the defined priorities and search history. Currently, two search algorithms are supported: - Grid Search: Exhaustively explores all configurations in a structured manner, ensuring a complete search of the space. - Random Search: Randomly samples configurations, providing more flexibility and potentially quicker results for large search spaces.
The search algorithm is designed to intelligently explore the configuration space to find high-performing settings for the quantization process.
Model Quantizer
After a configuration is sampled, the Model Quantizer is responsible for quantizing the model using the selected configuration. It takes three inputs: - The model to be quantized. - The quantization configuration, which defines the general approach (for example, precision, layer types). - The sampled configuration, which specifies specific tuning parameters (for example, quantization range, rounding methods).
The Model Quantizer utilizes existing APIs to perform the quantization process, producing a quantized model as output.
Evaluator
After the model is quantized, the evaluator assesses its performance based on certain metrics. There are two possible evaluation scenarios: 1. Custom Evaluator: If you provide an evaluator, it is used to measure the performance of the quantized model. The evaluator is expected to include a test dataset, execution runtime details (such as ONNX model execution), and a metric for evaluation (for example, accuracy, inference speed).2. Built-in Evaluator: If no custom evaluator is provided, the built-in evaluator is used. This evaluator relies on a test dataset (for example, a pre-defined datareader for quantization tasks) and calculates metrics like L1 or L2 norm to evaluate the model’s performance.
The evaluator returns the evaluation results, which are then used to guide the search process.
Stop Condition
The stop condition evaluates the results provided by the evaluator and determines whether the search process should terminate. There are several criteria for stopping:- If the performance of the quantized model is within a predefined tolerance level (as specified in the configuration), the configuration is added to the list of candidate solutions.- If the number of candidates meets the desired threshold, the search loop terminates.- If the maximum number of iterations or time allocated for the search process is exceeded, the loop is also stopped.
The stop condition ensures that the search process concludes either when a satisfactory set of configurations is found or when the time/resources allocated for the search are exhausted.
Two-Stage Search
When two_stage_search is set to True, Auto Search will first look for the best configuration within the Calibration search space. Based on the best configuration found in Calibration, it will then proceed to search for the best configuration within the FastFinetune search space. To enable two_stage_search, set the corresponding option in the auto_search_config:
class Auto_search_config:
# ... other auto search configs
two_stage_search = True # Default value is False
Important notes:- Search Space Requirements:The final search space (which may consist of multiple search spaces) must contain both Calibration and FastFinetune parts. If either of these is missing, the two_stage_search parameter will be ineffective, and the auto search will proceed with the standard search process.- FastFinetune Configuration:Ensure that the include_fast_ft parameter is set to True in either the quant_config or auto_search_config. This will ensure that the FastFinetune phase can proceed correctly. Without this setting, the FastFinetune search will not take place.- Parallel Computing:Both Calibration and FastFinetune phases currently do not support parallel computation.- Search Space Size:Since the purpose of two_stage_search is to exhaustively search for the best Calibration and FastFinetune configurations, the stop conditions for the search process will be disabled. To save time, it is recommended to keep the search spaces for both Calibration and FastFinetune small.
Advanced-Fastft Search
When advanced_fastft_search is set to True, Auto Search will look for the best configuration which include one of or both NumIterations and LearningRate in FastFinetune. The parameters used in advanced_fastft_search are composed of:
“sampler_algo”: defines the sampling strategies used to suggest hyperparameter values during searching process. Here are samplers we can use (reference: https://optuna.readthedocs.io/en/stable/reference/samplers/index.html):- “TPE” (default): A Bayesian optimization approach.Balances exploration and exploitation. Works well for most general-purpose optimization tasks.- “Random”: Pure random sampling. Useful as a baseline or when you want unbiased exploration.- “CmaEs”: Based on Covariance Matrix Adaptation Evolution Strategy. Good for continuous and complex search spaces.- “GPS”, “NSGAII”, “QMC”: Specialized samplers for research or advanced use cases.
“direction”: Direction of optimization. Set “minimize” (default) for minimization and “maximize” for maximization.
“n_trials”: The number of trials for each process. Default value is 10.
If you wanna set parallel search for advanced_fastft_search, you can set:- CPU: “”n_jobs” greater than 1 and “search_devices” = “cpu”, for example “n_jobs” = 2 and “search_devices” = “cpu”- GPU: “”n_jobs” greater than 1 and “search_devices” = “cuda:0,1…”, for example n_jobs = 2 and search_devices = “cuda:0,1”To enable advanced_fastft_search, set the corresponding option in the auto_search_config:
class Auto_search_config:
# ... other auto search configs
advanced_fastft_search = True # Default value is False
n_jobs = 1
search_devices = "cpu"
advanced_fastft_params = {"sampler_algo": "TPE", "direction": "minimize", "n_trials": 10}
search_space = {
"extra_options": {
"FastFinetune": {
"NumIterations": [100, 200],
"LearningRate": [1e-3, 1e-7],
}
}
}
Important notes:- Search Space Requirements:Only search_space attribute in auto_search_config can make the search space work. Multiple search spaces are not supported. Only one of or both NumIterations and LearningRate are supported now.- FastFinetune Configuration:Ensure that the include_fast_ft parameter is set to True in the quant_config. This will ensure that the FastFinetune phase can proceed correctly.- Parallel Computing:Both CPU and GPU support parallel computation.
Joint-parameter Search
To account for the coupling between different search parameters and to reduce the overall search space, we designed a Joint-parameter search strategy. Specifically, parameters like NumIterations and LearningRate are combined into a single joint parameter, NumIterLR. By grouping well-matched parameter pairs together, we transform the original multiplicative search space into a smaller discrete space, thereby improving search efficiency and accelerating the optimization process. One example for Joint-parameter Search is like:
class Auto_search_config:
# ... other auto search configs
search_space = {
"include_fast_ft": [True],
"extra_options": {
"FastFinetune": {
"NumIterLR": [[100, 1e-4], [200, 1e-5]]
}
}
}
Important notes:This joint parameter is not applicable to the advanced_fastft_search method.
Flow Diagram#
Initialize auto search config and quantization config.
Build the search space based on the configuration.
Sample configurations using the search algorithm (grid or random search).
Apply the model quantizer to the selected configuration.
Evaluate the performance of the quantized model.
Check the stop condition: - If the result is within tolerance, add to candidates. - If the candidate count exceeds the threshold, stop. - If iterations or time limit is exceeded, stop.
Repeat steps 3-6 until the stop condition is met.
Usage#
To use the automatic search process for model quantization, you need to define the following:- Auto Search Config: This includes parameters like the number of iterations, expected time per configuration, tolerance levels, and the stop condition.- Quantization Config: Defines the quantization method, such as bit width, layer-wise quantization, and rounding methods.- Evaluator: If using a custom evaluator, provide the test dataset and evaluation metric. Otherwise, the built-in evaluator will be used.- Float Onnx Model: This model is the target model to be quantized.- DataReader: Defines the calibration dataset for model quantization.
Example Configuration:
from quark.onnx.auto_search import AutoSearch
from quark.onnx.auto_search import AutoSearchConfig
from quark.onnx import PowerOfTwoMethod, CalibrationMethod
auto_search_config = AutoSearchConfig
auto_search_config.search_space = {
"calibrate_method": [
PowerOfTwoMethod.MinMSE, PowerOfTwoMethod.NonOverflow, CalibrationMethod.MinMax, CalibrationMethod.Entropy,
CalibrationMethod.Percentile ],
"activation_type": [QuantType.QInt8, QuantType.QInt16],
"weight_type": [QuantType.QInt8, QuantType.QInt16],
"include_cle": [True, False],
"include_auto_mp": [False, True],
"include_fast_ft": [False, True],
"include_sq": [False, True],
"extra_options": {
"ActivationSymmetric": [True, False],
"WeightSymmetric": [True, False],
"CalibMovingAverage": [True, False],
"CalibMovingAverageConstant": [0.01, 0.001],
"Percentile": [99.99, 99.999],
"SmoothAlpha": [0.5, 0.6],
'FastFinetune': {
'DataSize': [500, 1000],
'NumIterations': [100, 1000],
'OptimAlgorithm': ['adaround', 'adaquant'],
'LearningRate': [0.01, 0.001, 0.0001],
'FixedSeed': [42],
}
}
}
auto_search_config.search_stop_condition = {
"find_n_candidates": -1,
"find_best_candidate": -1,
"iteration_limit": 1000,
"time_limit": 3600, # in seconds
}
auto_search_config.search_evaluator = None
auto_search_instance = AutoSearch(quantization_config, auto_search_config, float_onnx_model_path, calibration_data_reader)
searched_candidates = auto_search_instance.search_model()
Conclusion#
The Automatic Search for model quantization provides a systematic approach to explore different quantization configurations in search of the best-performing model. By leveraging intelligent search algorithms and efficient evaluation processes, this approach can significantly improve the accuracy and efficiency of model quantization, making it easier to deploy optimized models in real-world applications. Please refer to the Quark Auto Search Tutorial example <../tutorials/onnx/auto_search/onnx_auto_search_tutorial>.
FAQ#
- How can I view the results or progress of the auto search?
During the model search process, a log file is generated, in the current working directory, by default named auto_search.log. You can monitor this file to check the search progress, configuration, and intermediate/final results. It provides detailed information on each search step, making it easier to understand what is happening internally.
- What is the role of cache_dir during the search process?
The cache_dir is used to store temporary files, mainly for saving the inference outputs of float and quantized models generated by the built-in evaluator. It must have enough space to store at least two full inference outputs (float model inference outputs and quantized model inference outputs).
To avoid unexpected errors, please ensure that the cache_dir is empty before starting the auto search.