Using OCP MX (Microscaling)#
Introduction#
This tutorial explains how to use OCP MX data types with AMD Quark.
OCP MX is a new family of quantization data types defined by this specification and explored thoroughly in Microscaling Data Formats for Deep Learning.
The key feature of OCP MX is that it subdivides tensors into arbitrary blocks of elements that share a scale, instead of using a single per tensor scale like many other data types.
This allows for better accuracy with more fine-grained scaling while still reducing storage and computational requirements.
How to use OCP MX in AMD Quark#
1. Install AMD Quark#
Follow the steps in the installation guide.
2. Set the model#
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained("meta-llama/Llama-2-7b", torch_dtype="auto", token=<hf_token>)
model.eval()
tokenizer = AutoTokenizer.from_pretrained("meta-llama/Llama-2-7b", token=<hf_token>)
Retrieve the model from Hugging Face using their Transformers library.
The model meta-llama/Llama-2-7b is a gated model, meaning access must be requested and a Hugging Face token generated.
Replace all instances of <hf_token> with the token.
3. Set the quantization configuration#
from quark.torch.quantization.config.config import QConfig, OCP_MXFP8E4M3Spec, QLayerConfig
mxfp8_spec = OCP_MXFP8E4M3Spec(is_dynamic=False,
ch_axis=-1).to_quantization_spec()
mxfp8_config = QLayerConfig(weight=mxfp8_spec)
quant_config = QConfig(global_quant_config=mxfp8_config)
For OCP MX quantization, which always uses per-group quantization with group size 32, helper classes are available to instantiate the necessary tensor quantization spec:
For FP8 E4M3:
OCP_MXFP8E4M3Spec,For FP8 E5M2:
OCP_MXFP8E5M2Spec,For FP6 (E3M2):
OCP_MXFP6E3M2Spec,For FP6 (E2M3):
OCP_MXFP6E2M3Spec,For FP4 (E2M1):
OCP_MXFP4Spec,For INT8:
OCP_MXINT8Spec.
In terms of what element type to choose, according to Microscaling Data Formats for Deep Learning, INT8 can be used as a drop-in replacement for FP32 without any further work needed and FP8 is almost as good. However, FP6 and FP4 will generally require fine-tuning and will incur a minor accuracy loss.
How is the tensor turned into blocks?#
Reshaping of the tensor into blocks is controlled by ch_axis and group_size.
Let us use a tensor of shape (2,4) as an example:
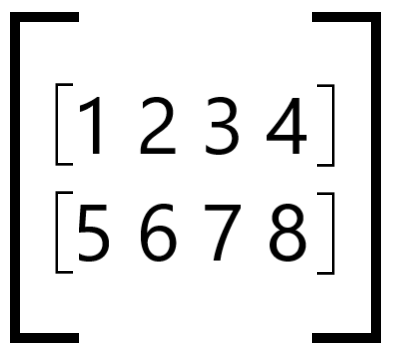
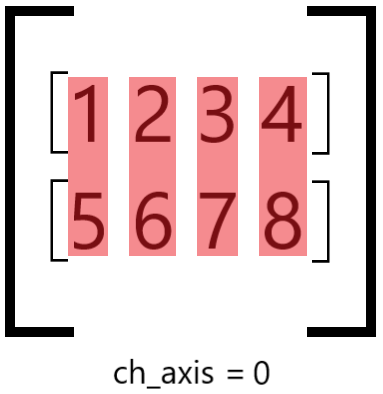
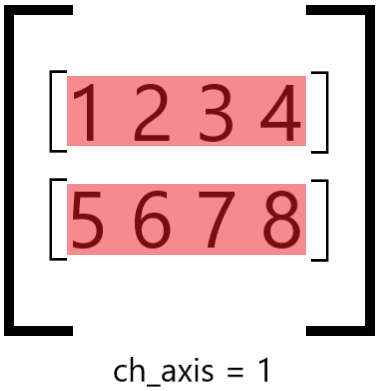
The parameter ch_axis determines along which axis elements will be grouped into blocks:
The group_size parameter determines how many elements to bunch together into a single block.
If it is larger than the number of elements along the axis, the block is padded with zeros until it reaches the correct size:
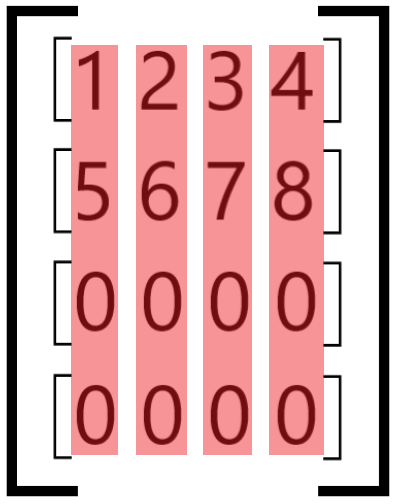
ch_axis = 0 and group_size = 4#
If the group_size is less than the number of elements, the axis is broken up into block tiles:
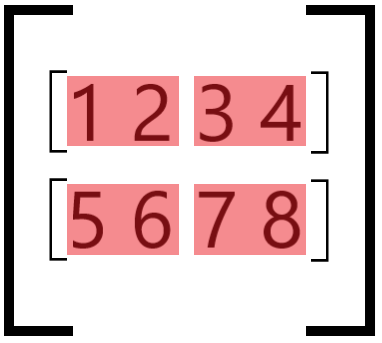
ch_axis = 1 and group_size = 2#
Each block has its own scale value.
4. Set up the calibration data (this is required for weight only and dynamic quantization as well)#
from torch.utils.data import DataLoader
text = "Hello, how are you?"
tokenized_outputs = tokenizer(text, return_tensors="pt")
calib_dataloader = DataLoader(tokenized_outputs['input_ids'])
If using static quantization, ensure the tensor shape of the calibration data matches the shape of the data intended for use with the model.
5. Apply the quantization#
from quark.torch import ModelQuantizer
quantizer = ModelQuantizer(quant_config)
quant_model = quantizer.quantize_model(model, calib_dataloader)
This step calculates the block scales, applies them to the element values, and performs quantization to the selected element data type.
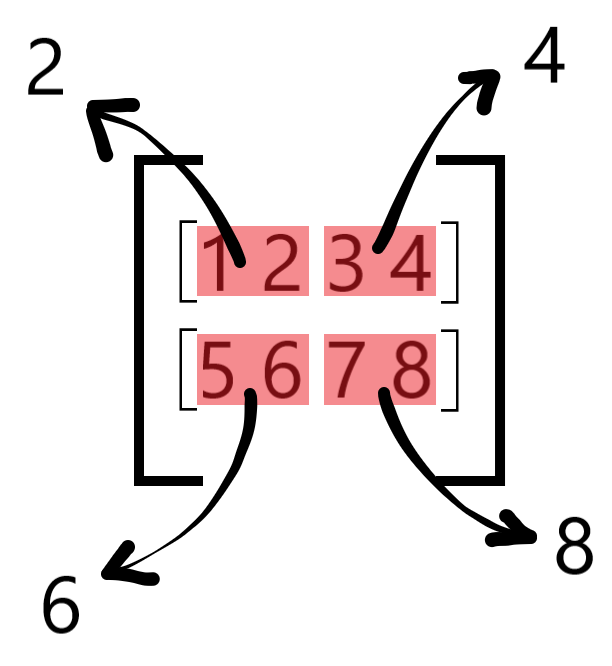
How are the scales calculated?#
Calculate the maximum absolute value for every block:
Using this value, calculate the shared exponent by:
Getting its log2 value,
Rounding it down to the nearest integer power, and
Subtracting the maximum exponent value the chosen element data type can represent.
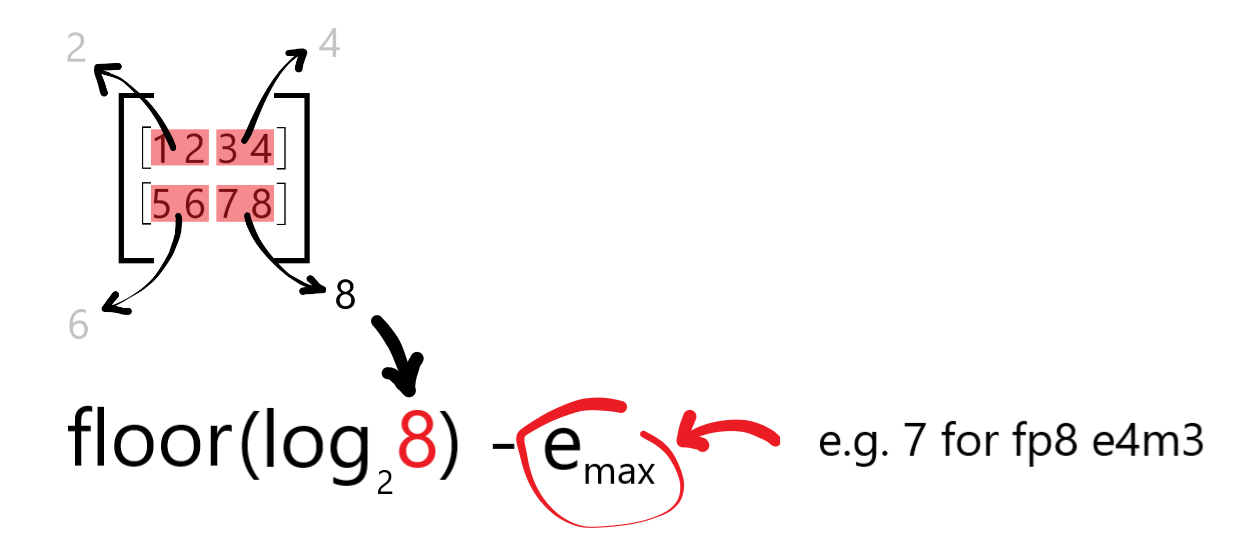
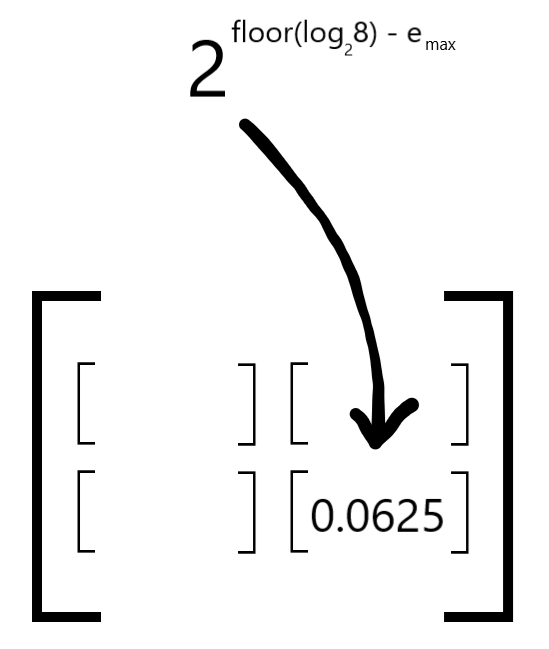
Finally, raise 2 to the power of the shared exponent to obtain the scale:
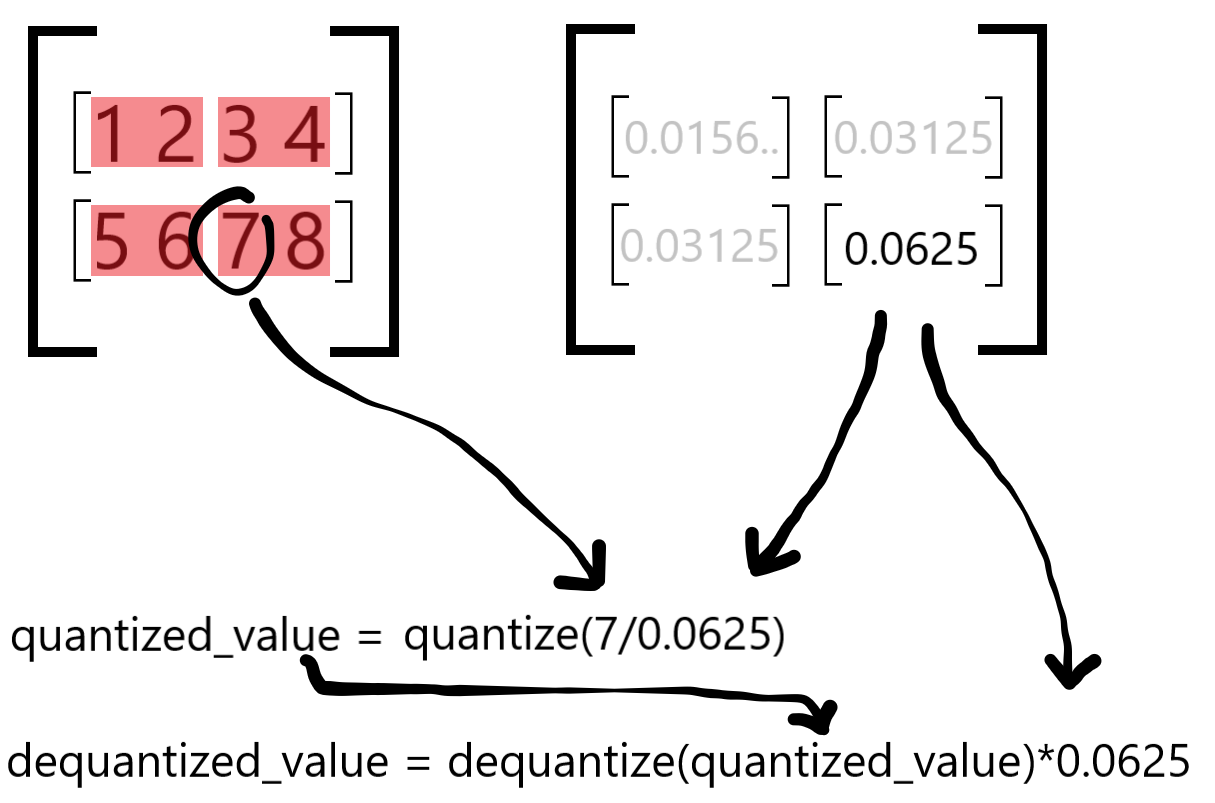
How are the scales used?#
Conclusion#
Congratulations! By following the steps above, you should now have a model quantized with MX data types ready for inference.
This tutorial also provides a better understanding of what MX means and why it might be beneficial to use.