Best Practice for Ryzen AI in AMD Quark ONNX#
This topic outlines the best practice for Post-Training Quantization (PTQ) in AMD Quark ONNX. It provides guidance on fine-tuning your quantization strategy to meet target quantization accuracy.
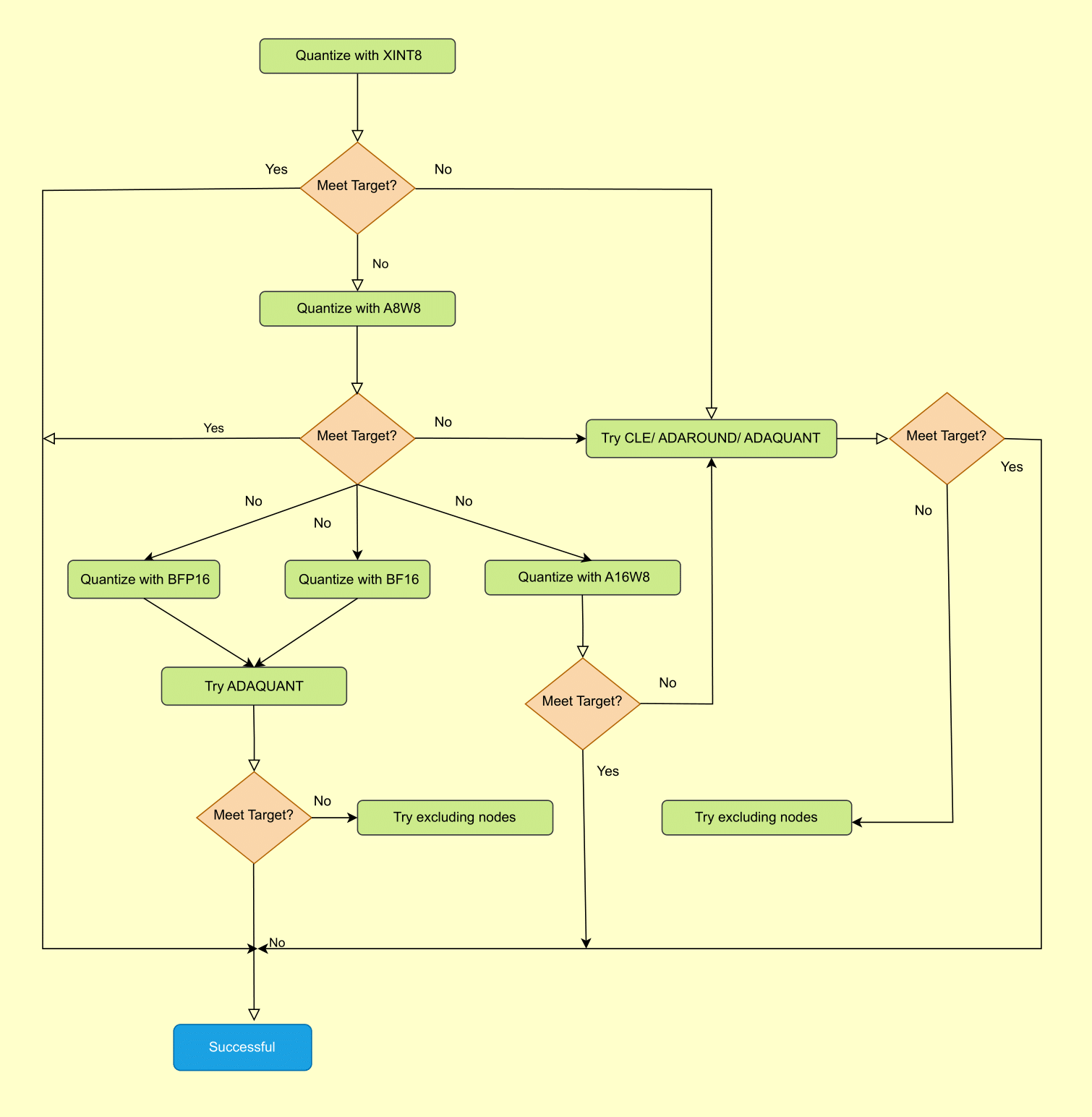
Figure 1. Best Practices for Quark ONNX Quantization#
Pip Requirements#
Install the necessary python packages:
python -m pip install -r requirements.txt
Prepare model#
Download the ONNX float model from the onnx/models repo directly:
wget -P models https://github.com/onnx/models/raw/new-models/vision/classification/resnet/model/resnet50-v1-12.onnx
Prepare Calibration Data#
You can provide a folder containing PNG or JPG files as calibration data folder. For example, you can download images from microsoft/onnxruntime-inference-examples as a quick start. Specifically, you can provide the preprocessing code at line 63 in quantize_quark.py
mkdir calib_data
wget -O calib_data/daisy.jpg https://github.com/microsoft/onnxruntime-inference-examples/blob/main/quantization/image_classification/cpu/test_images/daisy.jpg?raw=true
Quantization#
XINT8
XINT8 uses symmetric INT8 activation and weights quantization with power-of-two scales. Typically, the calibration method uses MinMSE. Refer to the following sections, such as ADAROUND and ADAQUANT, for methods to improve quantization accuracy based on this configuration.
python quantize_quark.py --input_model_path models/resnet50-v1-12.onnx \
--calib_data_path calib_data \
--output_model_path models/resnet50-v1-12_quantized.onnx \
--config XINT8
A8W8
A8W8 uses symmetric INT8 activation and weights quantization with float scales. Typically, the calibration method uses MinMax. Refer to the following sections, such as ADAROUND and ADAQUANT, for methods to improve quantization accuracy based on this configuration.
python quantize_quark.py --input_model_path models/resnet50-v1-12.onnx \
--calib_data_path calib_data \
--output_model_path models/resnet50-v1-12_quantized.onnx \
--config A8W8
A16W8
A16W8 uses symmetric INT16 activation and symmetric INT8 weights quantization with float scales. Typically, the calibration method uses MinMax.
python quantize_quark.py --input_model_path models/resnet50-v1-12.onnx \
--calib_data_path calib_data \
--output_model_path models/resnet50-v1-12_quantized.onnx \
--config A16W8
BF16
BFLOAT16 (BF16) is a 16-bit floating-point format designed for machine learning. It has the same exponent size as FP32, allowing a wide dynamic range, but with reduced precision to save memory and speed up computations.
python quantize_quark.py --input_model_path models/resnet50-v1-12.onnx \
--calib_data_path calib_data \
--output_model_path models/resnet50-v1-12_quantized.onnx \
--config BF16
BFP16
Block Floating Point (BFP) quantization reduces computational complexity by grouping numbers to share a common exponent, thereby preserving accuracy efficiently. BFP offers both reduced storage requirements and high quantization precision.
python quantize_quark.py --input_model_path models/resnet50-v1-12.onnx \
--calib_data_path calib_data \
--output_model_path models/resnet50-v1-12_quantized.onnx \
--config BFP16
CLE
The CLE (Cross Layer Equalization) algorithm is a quantization technique that balances weights across layers by scaling them proportionally, aiming to reduce accuracy loss and improve robustness in low-bit quantized neural networks. Consider XINT8 as the example:
python quantize_quark.py --input_model_path models/resnet50-v1-12.onnx \
--calib_data_path calib_data \
--output_model_path models/resnet50-v1-12_quantized.onnx \
--config XINT8 \
--cle
ADAROUND
ADAROUND (Adaptive Rounding) is a quantization algorithm that optimizes the rounding of weights by minimizing the reconstruction error, ensuring better accuracy retention for neural networks in post-training quantization. Consider XINT8 as the example:
python quantize_quark.py --input_model_path models/resnet50-v1-12.onnx \
--calib_data_path calib_data \
--output_model_path models/resnet50-v1-12_quantized.onnx \
--config XINT8 \
--adaround \
--learning_rate 0.1 \
--num_iters 3000
ADAQUANT
ADAQUANT (Adaptive Quantization) is a post-training quantization algorithm that optimizes quantization parameters by minimizing layer-wise reconstruction errors, enabling improved accuracy for low-bit quantized neural networks. Consider XINT8 as the example:
python quantize_quark.py --input_model_path models/resnet50-v1-12.onnx \
--calib_data_path calib_data \
--output_model_path models/resnet50-v1-12_quantized.onnx \
--config XINT8 \
--adaquant \
--learning_rate 0.00001 \
--num_iters 10000
Exclude Nodes
Excluding some nodes means that these nodes are quantized. The method can improve quantization accuracy. Consider XINT8 as the example:
python quantize_quark.py --input_model_path models/resnet50-v1-12.onnx \
--calib_data_path calib_data \
--output_model_path models/resnet50-v1-12_quantized.onnx \
--config XINT8 \
--exclude_nodes "resnetv17_conv0_fwd; resnetv17_stage1_conv0_fwd"