Quark for Ryzen AI NPU#
This section provides guidance on leveraging AMD Quark to deploy quantized models on the Ryzen AI Neural Processing Unit (NPU). By utilizing the Ryzen AI Software, developers can seamlessly run optimized models trained in PyTorch or TensorFlow on Ryzen AI-enabled processors. Ryzen AI Software has integrated tools and libraries like AMD Quark, ONNX Runtime and the Vitis AI Execution Providers (EP) that facilitates efficient inference across various accelerators, including CPU and integrated GPU (iGPU), in addition to the NPU.
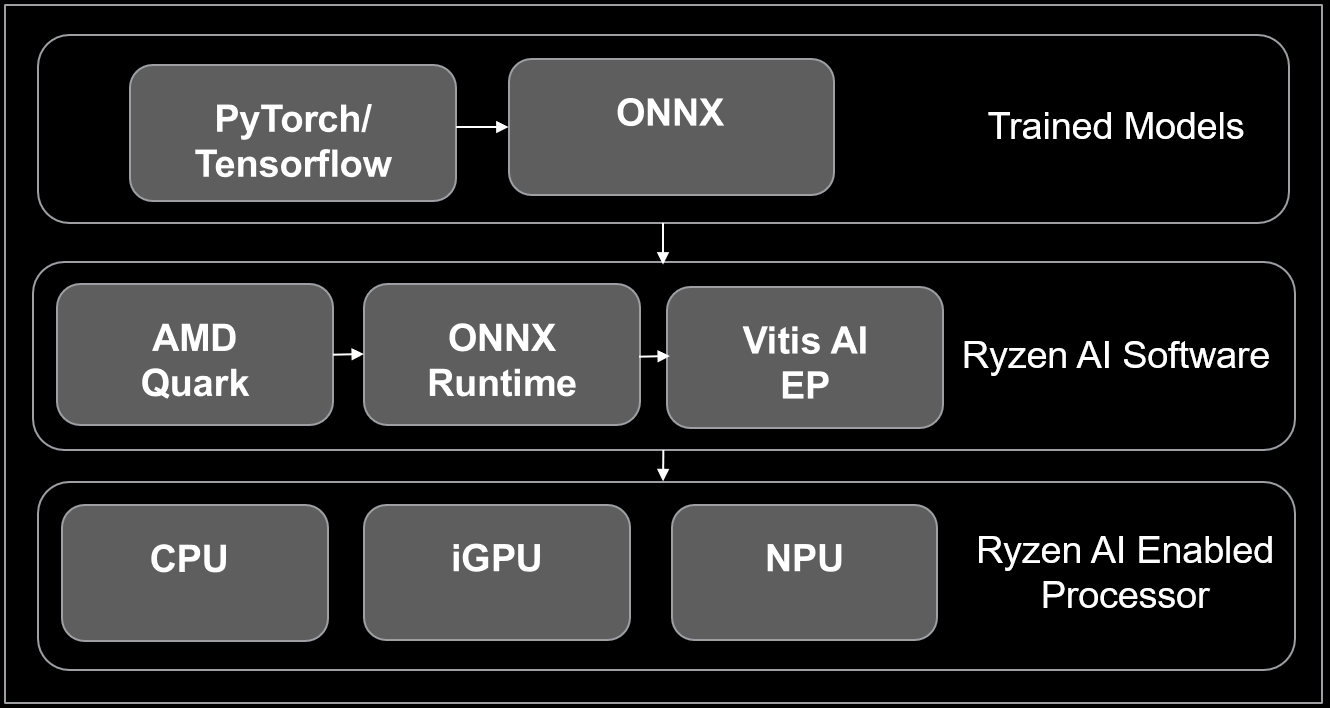
Development Flow Steps#
Trained Models: Trained models in popular frameworks such as PyTorch / TensorFlow are exported to ONNX format, to leverage ONNX Runtime to run on Ryzen AI supported processors.
Model Quantization: Use AMD Quark quantizer tools to convert your ONNX model into a quantized version, using the following quantization schemes: - For CNN models: INT8 or BF16 - For Transformer models: BF16 - For LLMs: INT4 or BF16
Deployment and Inference: Deploy the quantized on Ryzen AI-enabled hardware through ONNX runtime and Vitis AI Execution Provider.
AMD Quark provides advanced tools for model quantization. This documentation will help you navigate the capabilities of Quark to run with Ryzen AI.
Here you will find references on how you can leverage Quark to seamlessly run quantized models on the Ryzen AI NPU. Ryzen AI leverages ONNX models to represent models and execute them through ONNX Runtime.
To help you get started, we also have examples at the ONNX Examples page!
Resources
Quark also delivers a plethora of post-processing tools that might be of use for Ryzen AI. refer to the ONNX Tools to learn more!