Best Practices for Post-Training Quantization (PTQ)#
This topic outlines best practices for Post-Training Quantization (PTQ) in Quark PyTorch. It provides guidance on fine-tuning your quantization strategy to address accuracy degradation issues. Below, we use the model meta-llama/Llama-3.1-8B-Instruct and code files from Quark/examples/torch/language_modeling/llm_ptq as an example to demonstrate the methodology.
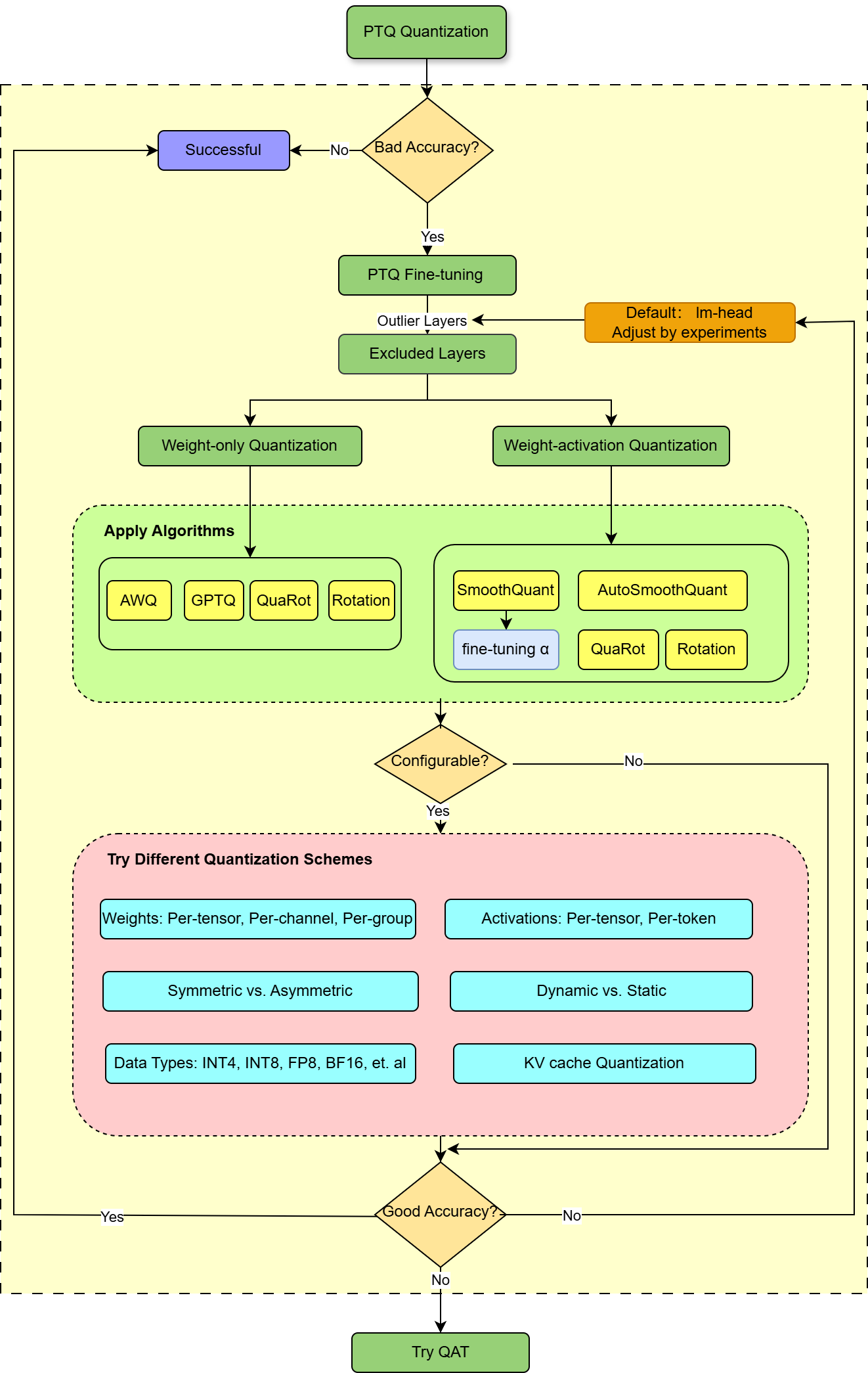
Figure 1. Best Practices for Quark Torch Quantization#
Exclude Outlier Layers#
Outlier layers can significantly degrade accuracy during quantization. Excluding these layers can enhance the performance of the quantized model. In Quark, you can exclude specific layers using the following commands.
cd Quark/examples/torch/language_modeling/llm_ptq/
exclude_layers="*lm_head *layers.0.mlp.down_proj"
python3 quantize_quark.py --model_dir meta-llama/Llama-3.1-8B-Instruct \
--quant_scheme w_fp8_a_fp8 \
--exclude_layers $exclude_layers \
Apply Quantization Algorithms#
Quark supports various quantization algorithms specifically designed for Large Language Models (LLMs). You can experiment with the following algorithms to enhance accuracy.
AWQ (Activation-aware Weight Quantization)
AWQ determines optimal scaling factors for smooth through grid search and is widely used in low-bit weight only quantization (e.g. W4 quantization with group-size 128). The algorithm can be used in the following command.
python3 quantize_quark.py --model_dir meta-llama/Llama-3.1-8B-Instruct \
--quant_scheme w_uint4_per_group_asym \
--group_size 128 \
--dataset pileval_for_awq_benchmark \
--quant_algo awq
GPTQ
This method is primarily used for low-bit weight-only quantization (e.g. W4/W3 per-channel). It quantizes weights column by column, minimizing second-order approximation errors.
python3 quantize_quark.py --model_dir meta-llama/Llama-3.1-8B-Instruct \
--quant_scheme w_uint4_per_group_asym \
--dataset wikitext_for_gptq_benchmark \
--quant_algo gptq
SmoothQuant
SmoothQuant reduces activation outliers by shifting the quantization challenge from activations to weights. The parameter \(\alpha\) controls the degree of merging. If you find the accuracy is not good after using SmoothQuant, please consider finetuning the value of \(\alpha\) in ./models/llama/smooth_config.json.
python3 quantize_quark.py --model_dir meta-llama/Llama-3.1-8B-Instruct \
--quant_scheme w_int8_a_int8_per_tensor_sym \
--pre_quantization_optimization smoothquant
AutoSmoothQuant
AutoSmoothQuant enhances SmoothQuant by automatically selecting the optimal \(\alpha\) values for each layer, guided by the Mean Squared Error (MSE) loss across blocks.
python3 quantize_quark.py --model_dir meta-llama/Llama-3.1-8B-Instruct \
--quant_scheme w_int8_a_int8_per_tensor_sym \
--dataset pileval_for_awq_benchmark \
--quant_algo autosmoothquant
QuaRot
QuaRot eliminates activation outliers using a rotation technique (Hadamard transform). Quark supports QuaRot algorithm, which can be used as follows.
python3 quantize_quark.py --model_dir meta-llama/Llama-3.1-8B-Instruct \
--quant_scheme w_int8_a_int8_per_tensor_sym \
--pre_quantization_optimization quarot
Rotation
QuaRot employs an online Hadamard transform in its algorithm, requiring kernel support for hardware deployment. Inspired by QuaRot and QServer, Quark introduces the “Rotation” method, which enhances accuracy without requiring kernel modifications.
python3 quantize_quark.py --model_dir meta-llama/Llama-3.1-8B-Instruct \
--quant_scheme w_int8_a_int8_per_tensor_sym \
--pre_quantization_optimization rotation
Try Different Quantization Schemes#
Experimenting with various quantization schemes can help improve accuracy. But keep in mind that how to select a appropriate scheme depends on your specific requirement and hardware constraints.
Key Quantization Schemes:
Weight-only vs. Weight-Activation Quantization: Activation quantization may lead to significant accuracy drop while weight-only quantization with extremely low bit-width may yield better results.
Quantization Granularity:
Weight quantization: Options include per-tensor, per-channel, or per-group quantization.
Activation quantization: Options include per-tensor or per-token quantization.
Dynamic vs. Static Quantization: For activation quantization, dynamic quantization often results in better accuracy than static quantization.
Symmetric vs. Asymmetric: Try experiment with symmetric or asymmetric quantization based on the model’s sensitivity to signed or unsigned values.
Data Types (Dtypes): Quark supports several data types, including INT4, INT8, FP8, MX-FPX, FP16, and BFloat16. Choose proper data type that best balances accuracy and efficiency for your model.
KV Cache Quantization: Skipping KV cache quantization typically results in better performance. Try applying this approach to the entire KV cache or specific parts of it may lead to better accuracy.
If accuracy issues persist after applying above methods, please consider trying Quark’s debug tool to identify outlier layers and exclude them from quantization.
Try QAT#
Quantization-Aware Training (QAT) often delivers superior performance compared to PTQ, as demonstrated in models like ChatGLM-3-6B. Please feel free to use Quark QAT method.