Bridge from Quark to llama.cpp#
Introduction#
Quark is a deep learning model quantization toolkit for quantizing models from PyTorch, ONNX and other frameworks. It provides easy-to-use APIs for quantization and more advanced features than native frameworks. Quark supports multiple hardware backends and a variety of datatypes with state of the art quantization algorithms integrated, such as AWQ, SmoothQaunt, GPTQ, and more.
After quantization, Quark can export the quantized model in different
formats. Quark has already implemented ONNX exporting and
JSON-Safetensors exporting. Now
we introduce GGUF exporting in this tutorial. Thanks to this feature,
users can obtain both high accuracy with Quark and high performance with
GGML based frameworks like llama.cpp.
What Is GGUF#
GGUF is
a file format that aims to store models weights for inference and also
executing them based on GGML runtimes. GGUF is a binary format that is
designed for fast loading, fast saving, and ease reading. Models are
traditionally developed using PyTorch or another framework, and then
converted to GGUF to be executed by
llama.cpp, a new popular
inference framework aiming to enable LLM inference with minimal setup
and state-of-the-art performance on a wide variety of hardware - locally
and in the cloud. Our experiments are all based on llama.cpp.
The structure of GGUF file is shown in Figure 1:
One may think of GGUF file as model config + Pytorch’s model state_dict.
The metadata key-value pairs correspond to model config while the
tensors info key-value pairs + tensors data correspond to model
state_dict. The quantization process actually converts tensors in fp32
or fp16 to tensors in other datatypes with less memory usage and more
computing efficiency. GGUF exporting is mainly about writing quantized
tensors to tensor part of GGUF file in appropriate format.
How Does Quark Do Quantization#
Quark implements quantization by inserting quantization operators before and after normal operators, as shown in Figure 2. Quantizers are quite versatile as to support for a several datatypes and quantization schemes.
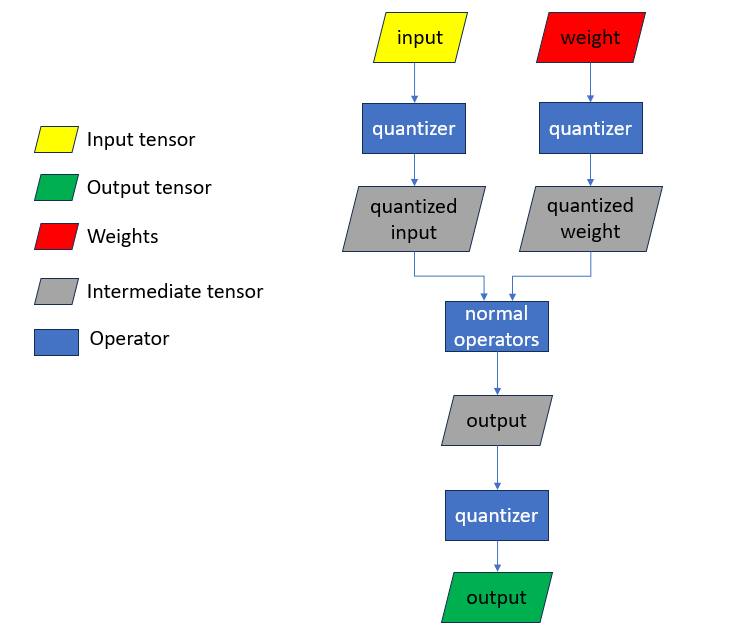
Quantizers are stateful containing information of datatypes and quantization schemes, such as scale, zero_point, group size for per-group quantization, etc. Exporting is to store weights and quantizer states in some format.
How to Use GGUF Export in Quark#
Step 1: Quantize Your Model#
There’s a handy API named ModelQuantizer in Quark. After
Initializing quantization related configs, a simple method call
quantizer.quantize_model can get work done.
# 1. Set model
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained("llama2-7b")
model.eval()
tokenizer = AutoTokenizer.from_pretrained("llama2-7b")
# 2. Set quantization configuration
from quark.torch.quantization.config.type import Dtype, ScaleType, RoundType, QSchemeType
from quark.torch.quantization.config.config import Config, QuantizationSpec, QuantizationConfig
from quark.torch.quantization.observer.observer import PerTensorMinMaxObserver
DEFAULT_UINT4_PER_GROUP_ASYM_SPEC = QuantizationSpec(dtype=Dtype.uint4,
observer_cls=PerChannelMinMaxObserver,
symmetric=False,
scale_type=ScaleType.float,
round_method=RoundType.half_even,
qscheme=QSchemeType.per_group,
ch_axis=0,
is_dynamic=False,
group_size=32)
DEFAULT_W_UINT4_PER_GROUP_CONFIG = QuantizationConfig(weight=DEFAULT_UINT4_PER_GROUP_ASYM_SPEC)
quant_config = Config(global_quant_config=DEFAULT_W_UINT4_PER_GROUP_CONFIG)
# 3. Define calibration dataloader (still need this step for weight only and dynamic quantization)
from torch.utils.data import DataLoader
text = "Hello, how are you?"
tokenized_outputs = tokenizer(text, return_tensors="pt")
calib_dataloader = DataLoader(tokenized_outputs['input_ids'])
# 4. In-place replacement with quantized modules in model
from quark.torch import ModelQuantizer
quantizer = ModelQuantizer(quant_config)
quant_model = quantizer.quantize_model(model, calib_dataloader)
Step 2: Export to GGUF#
There’s another easy-to-use API named ModelExporter to export
quantized models. To export GGUF models, call
exporter.export_gguf_model
# If user want to export the quantized model, please freeze the quantized model first
freezed_quantized_model = quantizer.freeze(quant_model)
export_path = "./output_dir"
model_dir = "<HuggingFace model directory>"
from quark.torch import ModelExporter
from quark.torch.export.config.custom_config import DEFAULT_EXPORTER_CONFIG, EMPTY_EXPORTER_CONFIG
config = DEFAULT_EXPORTER_CONFIG
exporter = ModelExporter(config=config, export_dir=export_path)
exporter.export_gguf_model(model, model_dir, model_type)
After running the code above successfully, there will be a .gguf
file under export_path, ./output_dir/llama.gguf for example. Users
can refer to user guide
for more information.
Step 3: Run with llama.cpp#
First, follow the official
docs
to build llama.cpp. After building successfully, There will be a few
executables, such as main for inference, perplexity for evaluation,
quantize for quantization, etc. Most of the executables take GGUF
model as input. We can evaluate the exported GGUF model to get the
perplexity value by running:
perplexity -m <path to exported GGUF model> -f <path to wiki.test.raw>
How Does It Work#
As mentioned above, the export API stores weights and quantizer states
into GGUF files. To export quantized models to valid GGUF models,
weights and quantizer states have to be encoded into valid GGUF
datatypes. There are some defined GGUF datatypes corresponding to
different quantization schemes, such as Q4_0, Q4_1, Q8_0,
Q8_1, etc. Users can refer to
ggml-common.h
for more datatypes and their definition. Some of the GGUF dtypes and
their corresponding quant schemes are shown in table 1.
GGUF dtype |
quant scheme |
|---|---|
Q4_0 |
symmetric uint4 per-group quantization with group size 32 |
Q4_1 |
asymmetric uint4 per-group quantization with group size 32 |
Q8_0 |
symmetric uint8 per-group quantization with group size 32 |
Q8_1 |
asymmetric uint8 per-group quantization with group size 32 |
As long as we find the GGUF datatype that matches the quantization scheme of the quantized model in quark, exporting to GGUF model is feasible. Thankfully, Quark supports a whole bunch of quantization schemes which match majority of defined GGUF datatypes.
Let’s take asymmetric int4 per-group quantization with group size 32
as an example, which is Q4_1 in GGUF spec. Quantizer state for this
quantization scheme are tensors for weight, scale and zero_point
for each group. For example, for weight of shape (N, 32), the shape of
scale tensor and zero_point tensor are both (N, 1). The definition
of Q4_1 in GGUF is as follows:
#define QK4_1 32
typedef struct {
union {
struct {
ggml_half d; // delta
ggml_half m; // min
} GGML_COMMON_AGGR;
ggml_half2 dm;
};
uint8_t qs[QK4_1 / 2]; // nibbles / quants
} block_q4_1;
Note that d is scale. m is minimum value of this block.
According to this definition, we need to convert weight + scale
tensor + zero_point tensor to Q4_1 blocks. There’s one last
question we are done. In quark, the storage is weight + scale +
zero_point, however, in GGUF the storage is weight + scale +
min_val. Are they equivalent to each other? The quant + dequant
processes of each storage are shown in equation (1) and (2)
respectively. \(x\) denotes float value. \(\hat{x}\) denotes the
value after quant and dequant.
If we set \(min\_val\) to the mininum value of the block, then Equation (1) and (2) are not equivalent, because Equation (1) could guarantee that 0 is still 0 after the transformation, but Equation (2) couldn’t. Equation (2) could guarantee that the mininum value of the block will keep the same after the transformation but Equation (1) couldn’t.
However, if we set \(min\_val\) to \(-s \times z\), they are equivalent. For \(min\_val = -s \times z\), we get:
It’s exactly the same as Equation (1).
Note that the process mentioned above doesn’t involve any quantization algorithms. Quantization algorithms are agnostic to GGUF exporting, which means quantized model with ANY quantization algorithms can be exported to GGUF model. As long as the exported GGUF model matches the quant scheme involved.
Experiments#
The dataset we used for evaluation is wikitext2. Download and
extract the wikitext-2-raw-v1.zip
file.
All the experiments are based on llama.cpp‘s commit
bdcb8f42221bc40c411150a009a3d3a30fa74722.
First, we use the script
convert_hf_to_gguf.py
to convert HuggingFace model Llama-2-7b to GGUF model named
llama-2-7b-float.gguf. Then, we use quantization feature of
llama.cpp to get quantized model named llama-2-7b-Q4_1.gguf with
command
quantize Llama-2-7b-float.gguf Llama-2-7b-Q4_1.gguf Q4_1
Next, we use quark to quantize Llama-2-7b with scheme of weight-only
int4 asymmetric alone with AWQ and export the quantized model to GGUF
model named quark_exported_model.gguf. Please Check out readme
examples/torch/language_modeling/README.md to get the command. Then, we
evaluate all the three models and get perplexities with the command
below:
perplexity -m quark_exported_model.gguf -f <path to wiki.test.raw>
The results are shown in table 2:
model |
perplexity |
|---|---|
llama-2-7b-float.gguf |
5.7964 +/- 0.03236 |
llama-2-7b-Q4_1.gguf |
5.9994 +/- 0.03372 |
quark_exported_model.gguf |
5.8952 +/- 0.03302 |
Note: There might be discrepency between the perplexity obtained from GGUF model and that from Quark evaluation. There are two main reasons:
The implementation of perplexity calculation is a little different between
llama.cppand Quark.For the experiment settings above, the quantization process in Quark is a little different from that in
llama.cpp. In Quark, only weights are quantized and activations kept in float32 without being quantized. However in ``llama.cpp``, activations are quantized to ``Q8_1`` implicitly when weights are in ``Q4_1``.
Note: Users should choose quant schemes that match llama.cpp as
much as possible.