SVD-Based Error Correction (SVDQuant)#
Note
In this documentation, AMD Quark is sometimes referred to simply as “Quark” for ease of reference.
AMD Quark supports SVDQuant, a post-training quantization algorithm introduced in SVDQuant: Absorbing Outliers by Low-Rank Components for 4-Bit Diffusion Models. It is the primary algorithm for aggressively quantizing diffusion models (for example, INT4 weights, optionally with INT4 activations) while preserving image quality.
How SVDQuant works#
Quantizing weights and activations to very low bit-widths (such as INT4) is hard because outliers in either tensor stretch the quantization range and waste most of the available bins. SVDQuant addresses this in two stages:
Smoothing. A migration of quantization difficulty between activations and weights, controlled by a strength
alpha(the same idea as SmoothQuant). This redistributes outliers so that neither tensor dominates the error.Low-rank error correction. The residual between the original weight and its quantized version still carries the hardest-to-represent components. SVDQuant decomposes that residual with an SVD and keeps a small low-rank correction branch in high precision (rank
svd_rank). At inference the layer output is the quantized main path plus this low-rank correction, so the bulk of the compute stays low-bit while the most error-sensitive directions are corrected in high precision.
In Quark the algorithm is implemented by SVDQuantProcessor (in
quark.torch.algorithm.svdquant). At a high level it:
collects activation statistics on calibration data;
computes per-layer smoothing factors (searching
alphaper layer whensearch_alphais enabled, otherwise using a fixedsmooth_alpha);performs the SVD decomposition and wraps each target layer in an
ErrorCorrectedModule(main quantized path +LowRankCorrectionModule);optionally quantizes the residual weights with GPTQ (Hessian-based, column-wise) instead of round-to-nearest when
use_gptqis set.
Algorithm choices#
SVDQuant exposes two important choices that trade compute for quality.
Residual quantization: RTN vs GPTQ. After the low-rank correction branch is
factored out, the remaining residual weights are quantized. By default this
uses round-to-nearest (RTN). Setting use_gptq=True instead quantizes the
residual with GPTQ – a Hessian-based, column-wise method that compensates for
quantization error using activation statistics. GPTQ is more expensive (it
collects and inverts Hessian information) but typically improves quality at very
low bit-widths. The gptq_* parameters control the GPTQ pass. In practice,
GPTQ mainly helps for NVFP4; for w4a4 and mxfp4 it does not reliably
improve over RTN (see the FLUX.1-dev benchmark below), so GPTQ is recommended
only for NVFP4 and plain RTN is a good default otherwise.
Smoothing strength: fixed alpha vs per-layer search. The smoothing strength
alpha balances quantization difficulty between activations and weights. With
search_alpha=False a single fixed smooth_alpha is used everywhere. With
search_alpha=True (the default) Quark searches alpha independently for
each layer, choosing the value that minimizes the post-SVD layer-output MSE on
calibration data (matching the original paper). The search is more accurate but
adds calibration compute; alpha_candidates and alpha_search_max_samples
tune its cost.
To choose between these options empirically for a given model and data type, see Calibrating and tuning SVDQuant below.
Configuring SVDQuant#
SVDQuant is configured with SVDQuantConfig and attached to a QConfig
through its algo_config list. The weight/activation data types come from
the QConfig itself (for example via build_quant_layer_config); the
SVDQuantConfig controls the algorithm.
Parameter |
Default |
Description |
|---|---|---|
|
32 |
Rank of the low-rank correction branch. Higher rank corrects more error (better quality) at the cost of a larger high-precision branch. |
|
0.5 |
Fixed smoothing migration strength, used when |
|
True |
Search |
|
None |
Optional explicit list of |
|
8 |
Number of calibration samples used during the per-layer |
|
(see below) |
Layer-name globs excluded from SVD decomposition (embeddings, in/out projections, etc.). |
|
256 |
Minimum layer dimension to apply SVDQuant to; smaller layers are skipped. |
|
False |
Quantize residual weights with GPTQ instead of round-to-nearest. |
|
4 / True / -1 / 128 / 0.01 / False |
GPTQ residual-quantization knobs (only used when |
Usage#
from quark.torch import ModelQuantizer
from quark.torch.quantization.config.config import QConfig, SVDQuantConfig
from quark.torch.algorithm.svdquant import build_quant_layer_config
qconfig = QConfig(
global_quant_config=build_quant_layer_config("w4a16"),
exclude=["*time_embedding*", "*conv_in*", "*conv_out*", "*correction*"],
algo_config=[SVDQuantConfig(
svd_rank=32,
search_alpha=False,
exclude_patterns=["*time_embedding*", "*conv_in*", "*conv_out*"],
)],
)
model = ModelQuantizer(qconfig).quantize_model(model, dataloader)
build_quant_layer_config provides ready-made schemes: w4a16 (INT4
weight-only), w4a4 (INT4 weight + activation), mxfp4 (OCP Microscaling
FP4 weights + dynamic FP4 activations), and nvfp4 (FP4 block-16 weights +
dynamic FP4 activations). All four are used the same way – only the
global_quant_config mode changes.
Note
*correction* must always be present in the QConfig.exclude list so
that the high-precision low-rank correction branch is not itself quantized.
Using SVDQuant with diffusion models#
SVDQuant is most commonly used to quantize diffusion submodules
(pipe.unet or pipe.transformer). Calibration data is collected from a
pipeline run with quark.torch.utils.diffusers.get_calib_dataloader, and the
model-specific exclude/exclude_patterns differ per architecture (SDXL,
SD3, Flux). See
Quantizing Diffusion Models with Quark
for complete, validated SDXL / SD3 / Flux examples, and
xDiT Inference with Quark Quantization
for running quantized diffusion models with multi-GPU distributed inference.
Native inference (MXFP4)#
By default a quantized SVDQuant model runs through the fake-quant / dequantize
(QDQ) emulation path, which reproduces the low-bit results but still computes in
high precision. On AMD GPUs (ROCm) with AITER installed, an MXFP4 SVDQuant model can
instead run with real low-bit GEMM kernels via
quark.torch.enable_native_inference:
from quark.torch import enable_native_inference, disable_native_inference
from quark.torch.quantization.utils import RuntimeOptions
# model was quantized with build_quant_layer_config("mxfp4") + SVDQuantConfig
n_converted = enable_native_inference(
model,
runtime_options=RuntimeOptions(
native_linear_mode="mxfp4",
svdquant_overlap_streams=False, # True: run the low-rank correction on a side CUDA stream
),
)
# ... run inference ...
disable_native_inference(model) # revert to the export-format layers
enable_native_inference detects SVDQuant ErrorCorrectedModule wrappers
and replaces each one with a fused layer that runs the MXFP4 residual GEMM
on AITER kernels and adds the high-precision low-rank correction branch;
bare MXFP4 QParamsLinear layers are converted to the plain MXFP4 native
linear. Setting svdquant_overlap_streams=True runs the low-rank correction
on a second CUDA stream so it overlaps the residual GEMM.
Note
Native inference currently supports an MXFP4 residual only for SVDQuant
(FP4 per-group, group_size=32); SVDQuant layers with a non-MXFP4 residual
are left on the eager path. Save the canonical Quark checkpoint before
calling enable_native_inference – the kernel-format weights live in
non-persistent buffers, so export/reload always uses the standard Quark
format regardless of whether native inference is active.
Calibrating and tuning SVDQuant#
The choices above – smoothing alpha, RTN versus GPTQ, and how many
calibration samples to use – interact, and the best combination depends on the
model and the target data type. Quark ships a calibration / grid-search
example, examples/torch/diffusers/svdquant_calibrate.py, to pick them
empirically. It can:
search the per-layer
alphaover a candidate grid (alpha_candidates);toggle GPTQ for the residual weights (
--gptq off|on|both);sweep the number of calibration samples (
--n_calib_samples).
Each (gptq, n_samples) cell uses the same flow as the other diffusers
examples – SVDQuantProcessor.apply() followed by
ModelQuantizer.quantize_model() – on a fresh pipeline, then scores the
result; the script writes a ranked results.json and summary.txt and
reports the best configuration.
SVDQuantProcessor already searches the per-layer alpha on a small number
of activations (alpha_search_max_samples) while using the full calibration
set for the smoothing statistics and GPTQ Hessian matrices, so searching the alpha on
a few samples and then continuing with the full calibration is the built-in
behavior of --search_alpha.
The scoring metric is selected with --eval_metric:
ref_image(default) compares generated images against a high-precision reference (PSNR / MSE, plusLPIPSwhen thelpipspackage is installed);module_msecompares the quantized submodule outputs against the reference outputs on held-out calibration inputs (no image generation, so it is the fastest);noneonly generates and saves one image per configuration.
# FLUX.1-dev, w4a16: staged alpha, compare GPTQ off vs on at 128 samples
python examples/torch/diffusers/svdquant_calibrate.py \
--model_id black-forest-labs/FLUX.1-dev --mode w4a16 \
--gptq both --n_calib_samples 128 --eval_metric ref_image
# SDXL, mxfp4: sweep the number of calibration samples
python examples/torch/diffusers/svdquant_calibrate.py \
--model_id stabilityai/stable-diffusion-xl-base-1.0 --mode mxfp4 \
--gptq off --n_calib_samples 64 128 256
See examples/torch/diffusers/README.md for the complete option list.
Note
Each grid cell reloads a fresh pipeline (quantization is destructive) and runs
its own per-layer alpha search, so keep grids small for large models such
as FLUX.
Benchmark results#
The following CLIP scores were measured on FLUX.1-dev with AMD Quark,
evaluated on 1000 MJHQ samples using openai/clip-vit-large-patch14. RTN and
GPTQ refer to how the SVDQuant residual weights are quantized
(round-to-nearest versus GPTQ).
Configuration |
CLIP score |
|---|---|
FP16 (reference) |
27.82 |
RTN W4A4 |
27.50 |
RTN MXFP4 |
27.41 |
RTN NVFP4 |
27.72 |
GPTQ W4A4 |
27.40 |
GPTQ MXFP4 |
27.36 |
GPTQ NVFP4 |
28.01 |
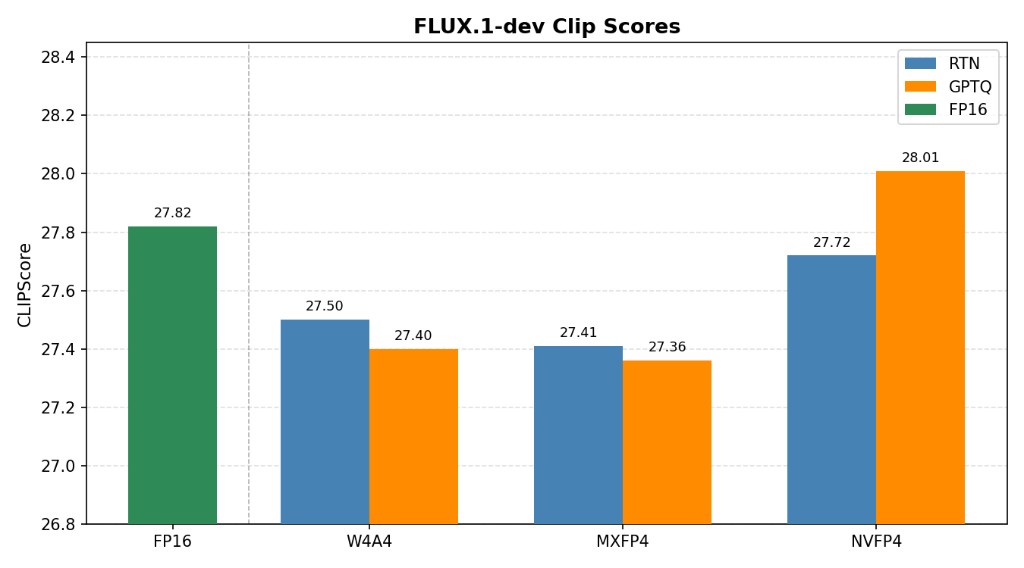
FLUX.1-dev CLIP scores for SVDQuant in W4A4, MXFP4, and NVFP4, comparing round-to-nearest (RTN) and GPTQ residual quantization against the FP16 reference.#
Across these low-bit configurations the CLIP score stays close to the FP16 reference, and NVFP4 in particular is competitive with full precision.